
Задача
- Подбор машинного масла.
- Сопутствующие товары по марке авто.
- Подбор реселлера.
- Продуктовые страницы с товарами конкретных марок и брендов.
Наша задача — собрать дашборд с верхнеуровневыми KPI для топ-менеджмента и дать командам возможность анализировать поведение пользователей на сайте: построить конверсионные воронки по основным продуктам, дать инсайты по популярности продуктов по странам присутствия Motul.
Решение задачи
Этап 1: Скачивание «сырых» данных
В качестве хранилища данных мы используем BigQuery. Источников данных у нас 8: 6 сайтов Motul, данные rest API сайта с мета-информацией о контенте продуктовых страниц и данные Hookit об активности в соцсетях.
Для загрузки данных мы используем стек технологий Singer + Meltano.
Этап 2: Моделирование данных
Стало понятно, что надо искать способ обогатить массив сырых данных недостающей информацией, прежде чем получится вывести данные на дашборд.
Для проектирования модели данных мы используем Минимальное Моделирование — подход, который позволяет одновременно разобраться в структуре данных и задокументировать ее.
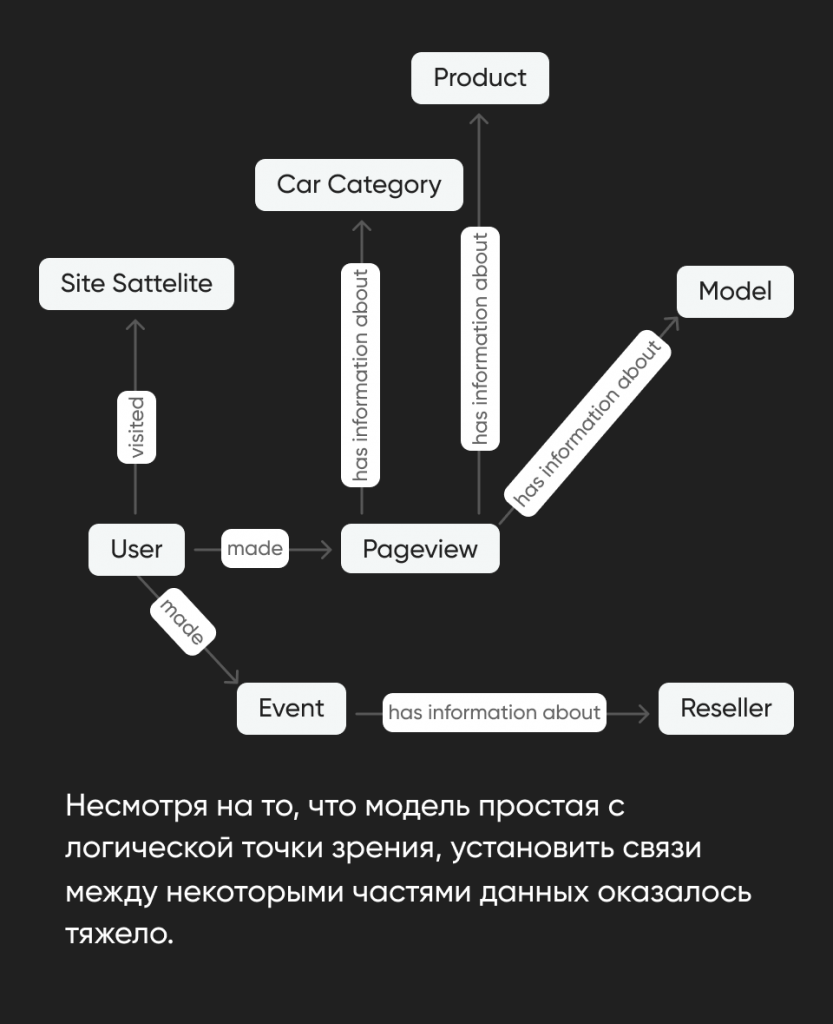
В результате моделирования мы выделяем в данных:
- Анкеры (это основные существительные предметной области, например, пользователь, ️страница, бренд и т.п.).
- Атрибуты (это характеристики анкеров, например, название страницы, дата регистрации пользователя и т.п.).
- Линки (связи между двумя анкерами, например, «пользователь открыл страницу»).
Найденные анкеры, атрибуты и линки мы сразу же документируем в Excel-файле. То есть описание финальных данных появляется раньше реализации.
Наша модель данных выглядит вот так:
Этап 3: Реализация Data API
Такой подход сильно упрощает тестирование данных: по сути, мы видим полный граф трансформаций каждого атрибута, поэтому если замечаем ошибку в данных, то можем проверить трансформации вплоть до сырых данных.
Также если каждый атрибут — это независимая таблица с данными в БД, то к задаче можно подключить сразу несколько аналитиков, которые могут работать над реализацией атрибутов параллельно.
Реализованные в виде независимых таблиц анкеры, атрибуты и линки мы называем Data API, потому что, по сути, это интерфейс к данным заказчика, с которым могут работать BI-отчеты, ML-модели и другие приложения.
Этап 4: Сбор витрины для PowerBI
Если мы дорабатываем логику работы с сырыми данными, мы меняем только логику в Data API, а данные всех широких таблиц для репортинга пересчитываются автоматически.
Этап 5: Визуализация данных в PowerBI
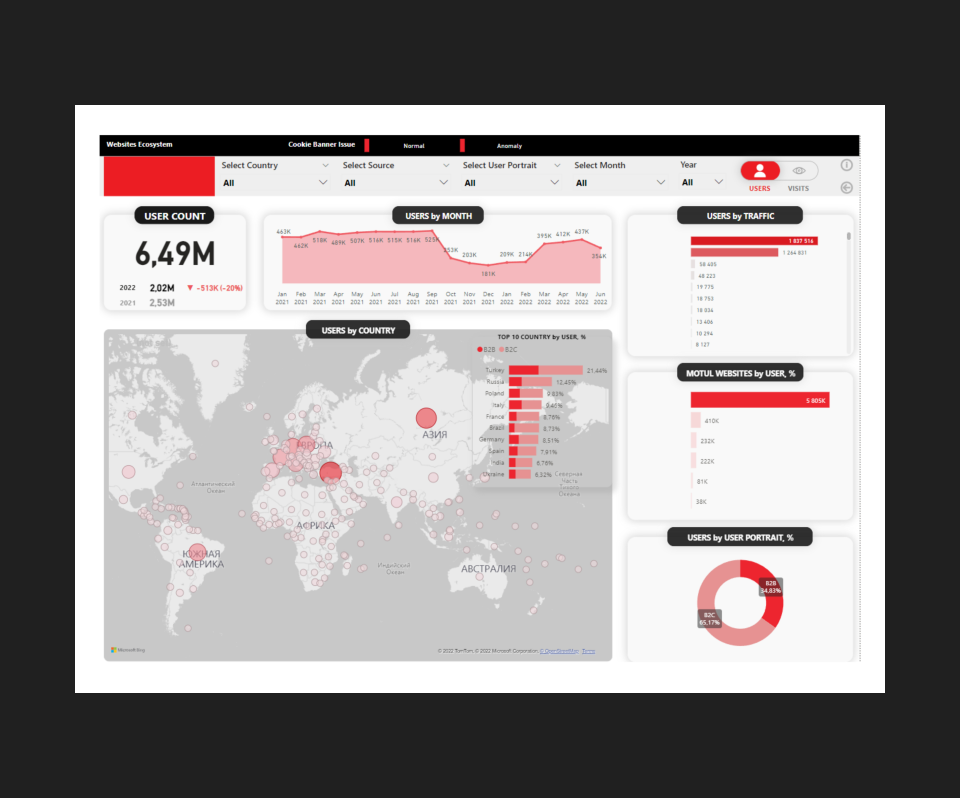
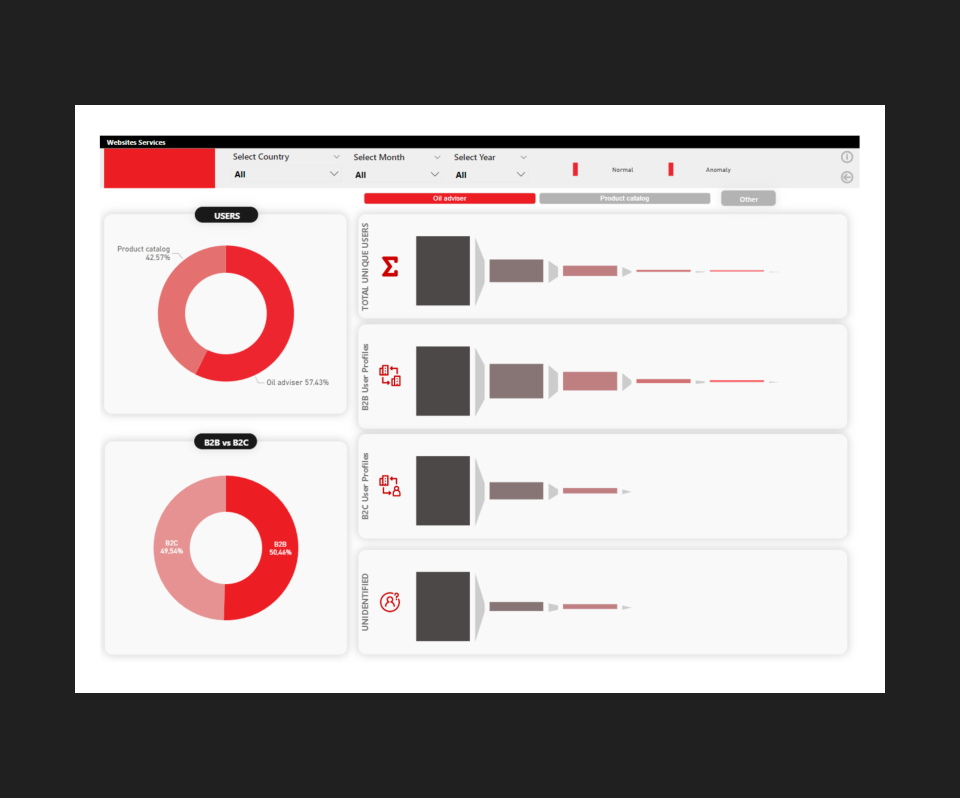
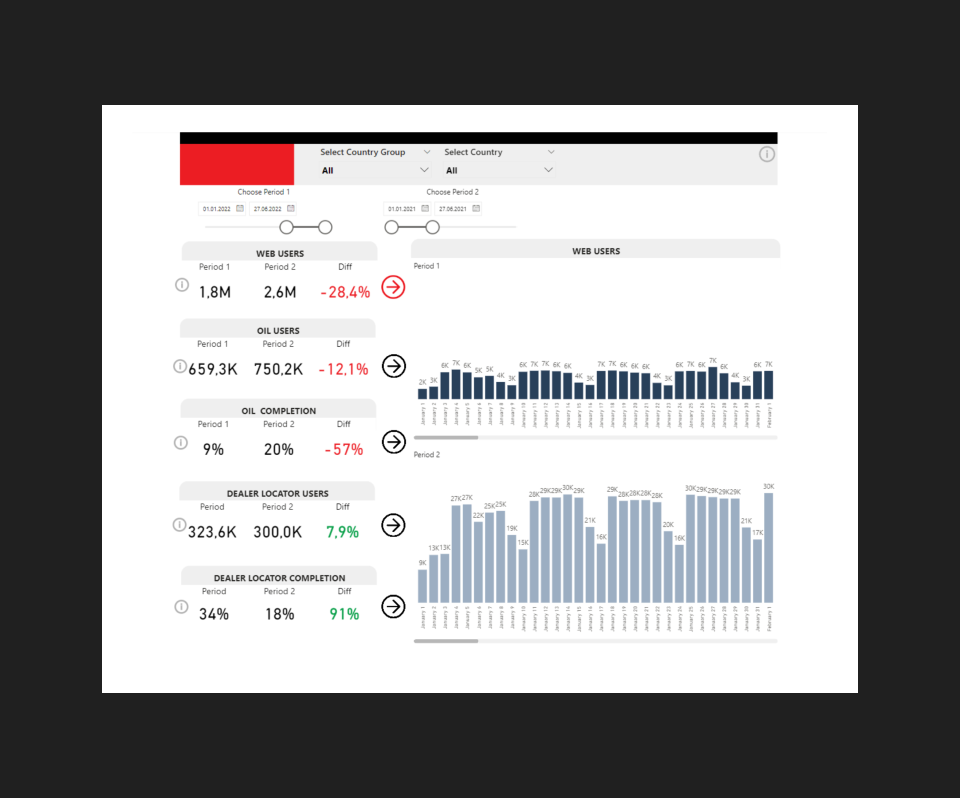
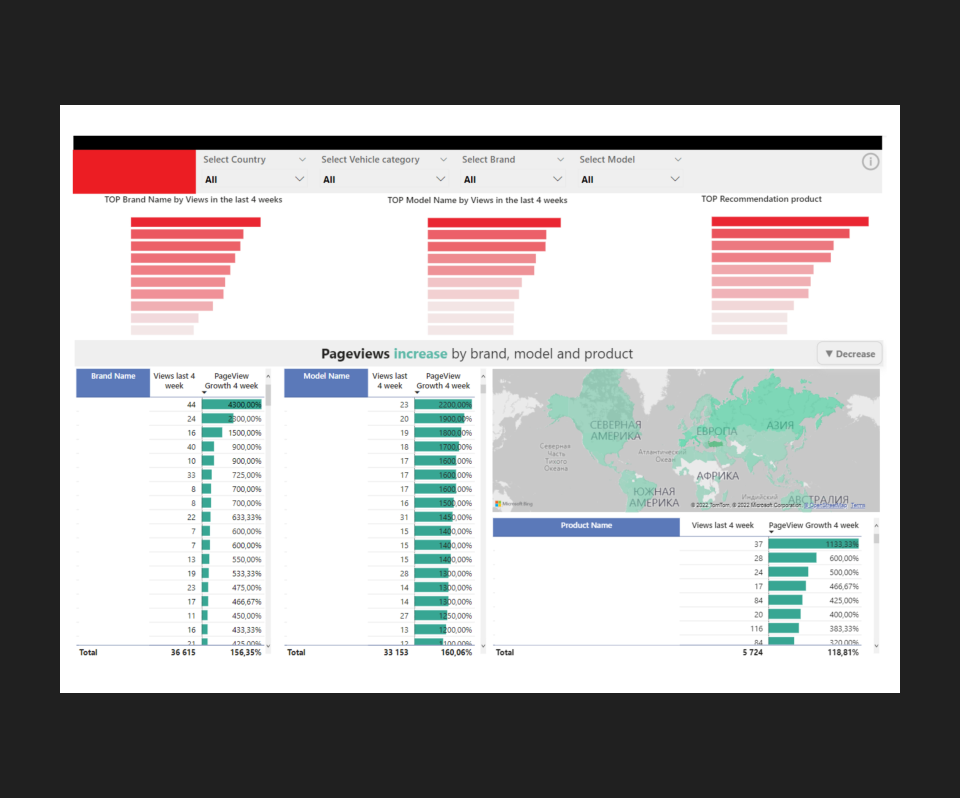
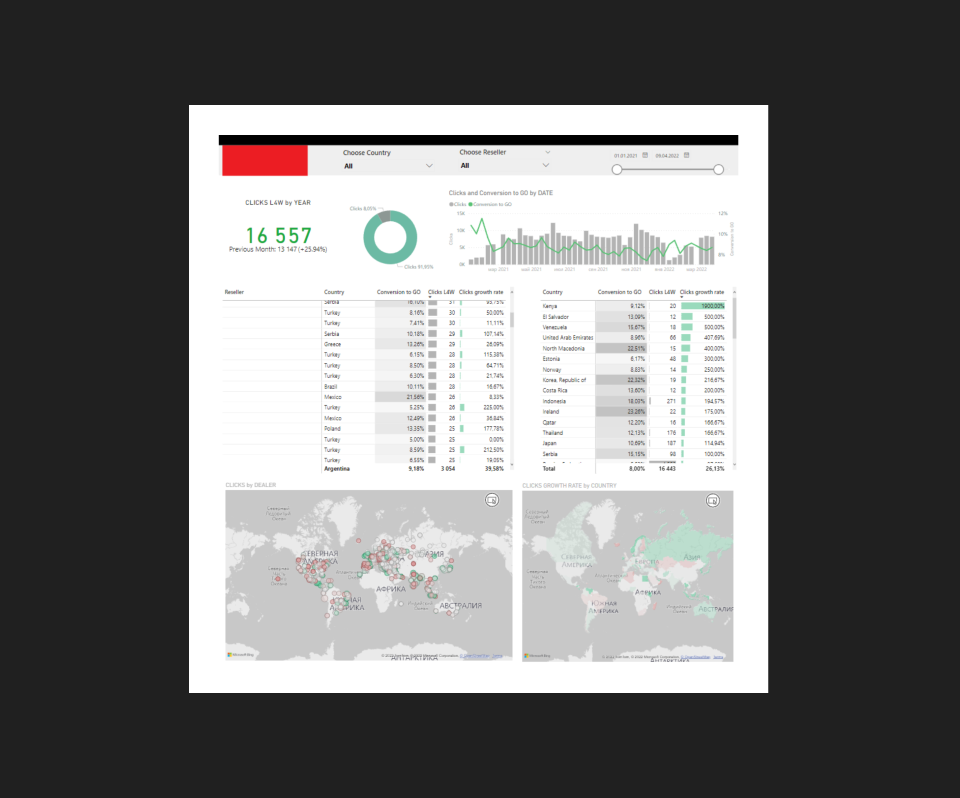
Результат
Автоматизировали отчетность по основным KPI.
Построили конверсионные воронки по продуктам.
Настроили единый дашборд из всех источников с возможностью анализировать поведение пользователей на сайте.
Проконсультировали заказчика по дальнейшим действиям по развитию digital-продукта.
Награды
-
В 2022 году проект занял 2 место в конкурсе Теглайн в номинации Лучшая работа с Bigdata



