Привет! Меня зовут Павел Лукьянов, я заместитель CTO в AGIMA. На одной из прошлых работ мы с ребятами попробовали внедрить так называемую чистую архитектуру на монолитном проекте. И это был интригующий опыт. Во-первых, мы начали намного рациональнее подходить к оценке задач. Во-вторых, заметно сократили time-to-market. А в-третьих, сильно разозлили наших аналитиков. Считаю, такими впечатляющими результатами стоит делиться.
Речь пойдет о разных моделях чистой архитектуры — богатой и бедной, немного поговорим о DDD, обсудим структуризацию кода под домен. В общем, опишу всё как было. А в качестве примеров буду использовать связку Django, Postgres, Redis и стек ELK с Grafana как основной инструмент для мониторинга.
Предпосылки: почему мы решили использовать чистую архитектуру
Немного о проекте. Это был монолит на Django с некоторым количеством сервисов. То есть по сути: часть — распределенный монолит, часть — полноценные микросервисы. Проект к тому моменту уже семь лет был в промышленной эксплуатации. Стало быть, нам временами приходилось иметь дело с легаси.
Еще из интересного: когда подключились к работе, увидели толстый слой представления и раздутые модели. Логика могла дублироваться несколько раз и лежать в абсолютно разных частях проекта. Покрытие росло, но мы не всегда понимали, какие тесты есть. У нас бывали не просто дубли тестов, а дубли фикстур.
В какой-то момент нам стало совсем уж неудобно работать с толстым слоем представления. К тому же бизнес-логику хотелось организовать в каком-то одном месте. Плюс система иногда вела себя совсем непредсказуемо и непонятно. И тогда, после нескольких бестолковых попыток добиться консистентности в базе данных, мы наконец решили переходить на чистую архитектуру.
Конечно, неразбериха в коде была не единственной причиной такого решения. Были и чисто организационные триггеры:
- Оценка задач в команде была завязана только на тимлиде — он решал, сколько времени примерно уйдет на задачу. Оттого оценки часто не совпадали с реальностью. В них просто не закладывали время на проектирование, ревью, риски. А мы были уверены, что чистая архитектура могла нам в этом помочь.
- Мы хотели писать в код, который бы максимально отражал бизнес-правила — то есть чтобы он не был оторван от реальности и чтобы задачи описывались сценариями использования. Особенно это было актуально, потому что мы следовали подходам «Документация как код» и «Инфраструктура как код».
- Поскольку мы имели дело с монолитом, все элементы системы были прочно связаны друг с другом. И если мы хотели изменить какую-то часть сервиса, мы ловили баги там, где не ожидали. Чистая архитектура должна была ослабить связь между объектами в хранилище.
Что это вообще такое — чистая архитектура
1. Чистая архитектура — это подход к проектированию систем, который предполагает независимость от фреймворка и вообще от внешних компонентов. А в нашем случае зависимость была, и еще какая! По сути, код для слоя представления, код в моделях и в целом архитектура были полностью продиктованы фреймворком. Чистая архитектура предполагает иной подход: мы выделяем слой use-кейсов, слой сущностей, UI и презентер. Эти слои — и есть наши фреймворки.
Поэтому в чистой архитектуре фреймворк можно реально использовать как инструмент, а не перестраивать весь проект под ограничения фреймворка.
2. Вторая отличительная черта чистой архитектуры — тестируемость. Это значит, что бизнес-правила могут быть протестированы без UI, без баз данных, без веб-сервера и без любого другого внешнего компонента. Например, у нас может быть фронтенд на React и мобилка на Flutter — и мы при этом всё равно можем менять контракты, не меняя бизнес-правила.
3. Чистая архитектура независима от информационных хранилищ. Можно поменять PostgreSQL на MongoDB или на любую другую субд при этом работа бизнес-правил не изменится.
4. А еще чистая архитектура — это независимость от внешнего сервиса. По факту слой use-кейсов изолирован от внешнего мира, ничего о нем не знает, он знает только о том, как работать в рамках бизнес-системы.
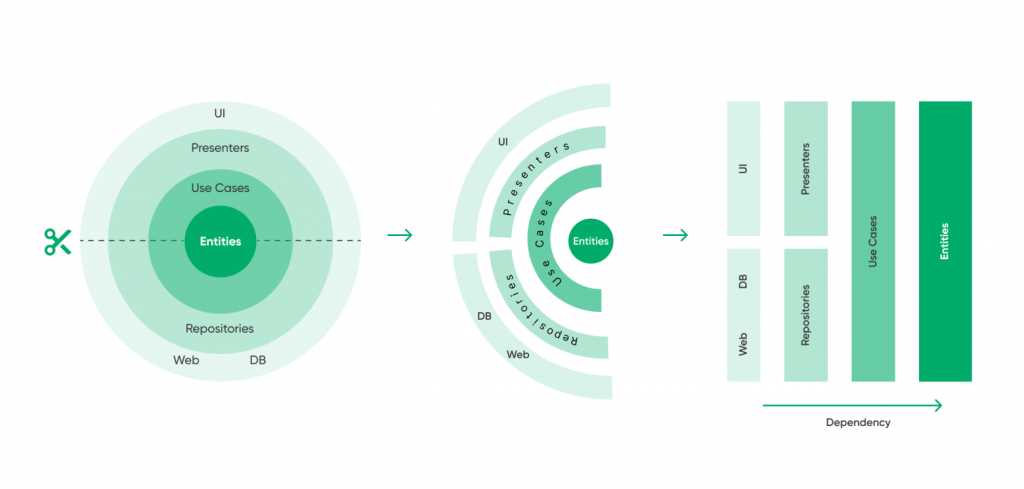
Как, по сути, работает чистая архитектура
При чем здесь бизнес
Выше я использовал термин «бизнес-правила». Это некие корпоративные политики, правительственные постановления или что-то в этом духе. Бизнес-правила не могут выступать в качестве требований к ПО, хотя, по сути, определяют ограничения и задачи разрабатываемой системы. И в итоге мы имеем такую ситуацию: бизнес понимает язык бизнес-правил, но язык требований к системе может и не понимать.
- Проще говоря: бизнес не поймет техническую терминологию из бизнес-требований, зато сможет провалидировать свои пожелания относительно будущего сервиса. Бизнес-правило: отказоустойчивость при заключении правительственных контрактов. Бизнес-требование: использование дата-центров, использование конкретных СУБД и т. п.
Когда мы правильно фиксируем бизнес-правила, сокращаются риски при разработке. Мы можем раньше выявлять неточности в требованиях и исправлять их. Как результат, мы не напишем неправильный и ненужный код. Наша затея с чистой архитектурой была отчасти связана именно с этим — мы хотели приблизить нашу разработку к реальным задачам заказчика.
Модели предметной области
Для чистой архитектуры важно понятие «модели предметной области». Каждая модель — какой-то элемент бизнес-логики или, иначе говоря, какое-то бизнес-правило. Это своего рода абстракция, которая описывает поведение сущностей внутри логики приложения. Скажем, для еком-проекта такими моделями могут быть заказ, товар и покупатель.
Существуют несколько типов моделей предметной области, но самые популярные две: богатая и бедная (анемичная).
- В богатой модели предметной области слой служб очень тонок, а иногда вообще отсутствует. Вся бизнес-логика заключена в сущностях (те самые «заказ» или «покупатель»), а те реализованы в виде методов внутри классов. В богатой модели сущности способны самостоятельно обеспечивать свои инварианты, что делает такую модель полноценной с точки зрения объектно-ориентированного подхода.
На примере принципа инкапсуляции мы можем объединять данные и операции по их обработке в одном месте, а также скрывать ненужные детали от пользователей обобщенной модели.
Бедная (она же анемичная) модель предметной области выглядит иначе: это некая совокупность классов без поведения, содержащих данные, необходимые для моделирования предметной области. Со стороны может показаться, что анемичная модель — это некий набор DTO, в которых нет никакой логики, а связь бизнес-правил и модели предметной области ослаблена.
Обычно аргументом против этого подхода становится то, что данные и способы их обработки оказываются разделены. Это нарушает один из главных принципов ООП-подхода, так как не позволяет модели обеспечивать собственные инварианты.
Однако мы всё равно выбрали анемичную модель. Благодаря этому каждый компонент у нас представлял некую единую абстракцию. Нам это помогло организовывать бизнес-правила и чисто инфраструктурные задачи в отдельных классах. Как следствие, связанность классов уменьшается, а это ровно то, чего мы и добивались.
- Посмотрим пример. У нас была доменная сущность X, которая в разных частях системы могла состоять из разных полей и вести себя по-разному. При богатой модели никакой из методов не смог бы полноценно наполнить ее, не затрагивая другие сущности. Если бы нам пришлось менять бизнес-правила, мы бы меняли все сущности, с которыми взаимодействует X. А мы этого не хотели.
Паттерны, которые мы использовали
В анемичной модели сущности представляют собой некий набор классов, которые не связаны с бизнес-логикой. По сути, это что-то вроде классов-контейнеров. Это значит, мы можем оперировать несколькими объектами, и внутри каждого будет разное количество данных. При этом мы решили наследовать одни сущности от других, когда нам это нужно, чтобы не дублировать код.
- Мы писали на Python и использовали библиотеку Pydantic. Но можно пользоваться любой. Кроме разве что attrs, в которой наследование сущностей работает криво. В итоге, мы могли использовать некие миксин-классы для сущностей. Предположим, в какой-то модели есть сущность «Клиент» и есть ее принадлежность «Пользователь клиента». В этом случае мы можем использовать сущность «Клиент» как миксин для сущности «Пользователь». Далее мы получаем требования к нашим сущностям в виде поддержки сериализации JSON, чтобы было удобно передавать из слоя в слой, в том числе в слои представления, и отдавать в пользовательский интерфейс.
Еще мы договорились, что однородные объекты у нас будут связаны с единым интерфейсом, но при этом смогут определять часть полей ниже себя — это своего рода симбиоз Entity Object и Value Object. При этом мы уходили от конкретного фреймворка: могли поменять одну библиотеку на другую без нервотрепки. Иными словами, требования чистой архитектуры мы удовлетворяли.
Unit of work
Нашим основным паттерном был Unit of work. Нас беспокоила неконсистентность данных, поэтому нам нужно было следить за состоянием сущностей. Unit of work нам в этом здорово помогал. К тому же паттерн уменьшал связанность слоев и фактически был главным ответственным за единство данных.
Теперь наше основное хранилище соответствовало принципу ACID, и мы могли спокойно роллбекать и коммитить изменения. Паттерн Unit of work позволял использовать любое постоянное хранилище и удобно тестировать код. Мы могли заменять сессии на уровне объекта, который содержит в себе набор различных хранилищ, и нам при этом не нужно было проводить изменения в других слоях.
В итоге мы использовали возможности ACID, но могли и перейти на сохранение состояния в Key Value Storage, чтобы получать состояния сущностей в каждый момент времени. Паттерн позволял полностью отделить сервисный слой — он ничего не знал о том, где данные и что с ними происходит. Сервисный слой просто описывал действия над сущностями.
Также у нас появилась возможность обновлять сразу несколько сущностей в рамках одного сервиса. А это невозможно в богатой модели. Unit of work должен был стать уникальным для каждого сервиса, но при этом переиспользовать существующий набор репозиториев и мапперов. Таким образом, каждый раз при написании нового функционала нам нужно было определиться, какие сущности мы обновляем и какие действия совершаем. Это было основой для нашего UoW, который вызывался из сервиса.
Data mapper
Если Unit of work — это высокоуровневый API для доступа к хранилищу, то низкоуровневым в нашей архитектуре был Data mapper — объект общения с внешними хранилищами. Он мог отвечать за преобразование одной сущности в другую.
В чистой архитектуре его часто объединяют с репозиторием. И это паттерн, который работает с хранилищами данных. При этом Mapper может отвечать за перевод сущностей из одной структуры в другую. В нашем же проекте он отвечал еще и за CRUD-операции с внешним источником данных.
При этом мы могли решить проблему по отделению кода предметной области от неких прикладных операций. До того как мы ввели репозиторий в спецификацию, эти три паттерна у нас были смешаны. Однако теперь все слои были разделены:
- слой, отвечающий за условия валидации и фильтрации;
- слой управления данными, о которых мы поговорим далее;
- слой, который организовывал доступ к хранилищу и выполнял роль некоего транслятора команд под конкретный внешний источник данных.
Из этих слоев фактически состоял репозиторий. Они и помогали ему общаться с хранилищами.
Репозиторий
Репозиторий — это объект работы с данными, то есть объект хранилища. Он ведет себя как коллекция неких доменных объектов с возможностью фильтрации по ним. У нас он отвечал за выборки данных. А еще он отделял наш код доменной области от некоторых прикладных операций, который мы хотели скрыть.
- Например, работа с фреймворком. Так как у нас работа с фреймворком происходила в маппере, репозиторий позволял нам скрыть это и, при ослаблении связи этих слоев, менять мапперы на лету. До этого мы использовался Active Record и ORM для фильтрации объектов, а теперь начали обращаться к методу репозитория, чтобы получить некий набор сущностей. Маппер же у нас теперь обеспечивал лишь перевод искомых сущностей на язык ORM, SQL и т. п. При этом условия фильтрации мы тоже старались выносить из репозиториев в спецификации.
Спецификацию мы использовали как объект для описания условий валидации или фильтрации сущностей. Оговорюсь, что описание условий фильтрации мы делали при помощи средств фреймворка — так удобнее. Но мы поняли, что, если нам реально нужно будет их переписать на что-то другое, это будет дешевле, чем заново разрабатывать свой доменной язык для фильтрации объектов.
Спецификация
Спецификация — это паттерн, который позволял нам описывать условия валидации и фильтрации сущности отдельно от слоя хранилищ и от слоя сущности. Это полностью удовлетворяло условию бедной модели предметной области. Нам это было важно, так как мы не могли объединять одинаковые сущности в одну общую с максимальным количеством необязательных полей. При этом мы могли использовать разные спецификации в зависимости от контекста бизнес-логики.
Главное преимущество этого паттерна — что для реализации конкретного правила появляется набор явно описанных правил фильтрации и валидации. А это значит, что вопросов типа «почему ответ в свое представление был именно таким?» больше возникнуть не могло. У нас было определенное место в структуре проекта, где все условия были описаны.
- На полях замечу, что не стоит с этими условиями сильно упарываться. Есть условия, которые в принципе нет смысла класть в спецификацию. Всё-таки спецификация должна содержать какие-то действительно сложные условия, а не примитивные и интуитивно понятные.
При этом мы взяли абстракцию Validation Rule и написали для этих спецификаций валидатор. По контрактам он настраивается так, как нам нужно. Это позволяет отдавать ошибку в слой представления в удобном нам формате.
Как связаны Use-кейсы + Unit of work + сервисы
Как я упомянул выше, в чистой архитектуре выделяют различные слои, и один них — слой сервисов. Там мы храним бизнес-логику или бизнес-правила. Но существует и слой Use-кейсов. В нем заключен конкретный сценарий использования. Со временем мы поняли, что можем столкнуться с переиспользованием доменных сервисов, однако Use-кейсы будут уникальными. Следовательно, Unit of work связан непосредственно с Use-кейсом и обеспечивает его необходимым набором репозиториев и мапперов. Use-кейс в свою очередь может состоять чисто из методов репозитория или из нескольких методов различных сервисов.
- Например. У нас может быть клиент и его пользователь. Предположим, пользователь хочет поменять аватарку и имя. При этом у сущности клиента есть доступ к некоему реестру сотрудников — там мы тоже должны внести изменения. Значит, имеет смысл поделить логику: изменение аватара — вывести в так называемый инфраструктурный сервис, изменение в реестре — вывести в некий доменный сервис, а затем написать метод для репозитория пользователя, в котором будут изменения его данных. При этом нужно объединить всё это конкретным сценарием.
Когда возникла четкая связь между слоем хранилища, слоем пользовательского сценария и слоем бизнес-правил, мы начали сильно нервировать системных аналитиков. Они описывали требования к системе, а разработчик отныне должен был знать о бизнесе намного больше. Теперь он мог прийти с неожиданным и очень конкретным вопросом: «В этом случае уведомление явно не должно отправлять, но в каком тогда должно?» И аналитику приходилось разбираться, уточнять, копаться.
Ранее на 9 разработчиков нам хватало полтора аналитика. Когда перешли на чистую архитектуру, их количество пришлось увеличивать вдвое — один аналитик на троих разработчиков. При этом точность оценок и наполненность задачами в спринте возросли.
Энтропия и когнитивная нагрузка
Мы перешли на чистую архитектуру в том числе и потому, что хотели сократить энтропию системы. В команде не было жестких стандартов, а были лишь общие договоренности. Но чистая архитектура помогла преломить эту ситуацию.
- Теперь разработчик должен был продумать дизайн задачи еще до ее реализации. Это позволяло уменьшать трудозатраты: многие нестыковки в требованиях мы выявляли еще до того, как переходили к написанию кода. Параллельно начали вести реестр архитектурных решений, в котором в том числе фиксировали решение некоторых типовых задач. Всё это позволило нам вести историю изменения архитектуры, а аналитики и проджекты могли в любой момент обратиться к решениям команды, которые были описаны, обоснованы, внедрены и протестированы.
В итоге у нас начала уменьшаться толщина слоя сервисов — код теперь было намного проще переиспользовать: сервисы постоянно объединялись и реорганизовывались. Один Use-кейс мог использоваться в разных частях системы. Это привело к сокращению количества багов. А команда при этом начала глубже погружаться в проект, разработчику было важно понимать паттерны, которые мы использовали.
Был и еще один бонус, которого мы не ожидали, — наблюдаемость. Паттерн Unit of work позволил нам нарезать систему на набор процессов. В системе можно было увидеть два графика. Они отражали действия пользователей в разное время: когда они начинают работать, когда менее активны, что обычно делают в системе. К тому же появилась связь с другими инструментами — в нашем случае это были Elastic APM.
Теперь видно ошибки в системе и появилась возможность лучше расследовать инциденты
Приятные результаты
- До введения описанного набора паттернов и и вообще до чистой архитектуры разработчик мог, например, не запустить фронт и не понимать, как его изменения повлияют на бизнес. После мы получили готовый чек-лист того, как правильно приступать к задаче. В нем были названы четкие шаги и приведен список артефактов, которые нужно было получить по итогу.
- Стало легче оценивать задачи и производить валидацию оценок. Я был лидом проекта, и мне стало проще отслеживать, что происходит в задачах, куда были добавлены изменения и какие это были изменения.
- Мне было проще понять, какой Use-кейс можно переиспользовать в другой части системы, потому что я стал лучше ее понимать. А понимал я ее лучше, потому что у меня не было необходимости погружаться глубоко в код. А разработчикам было проще, потому что они теперь ориентировались на Use-кейсы. Фактически у нас появилось коллективное владение кодом.
Кому подойдет чистая архитектура
Внедрение чистой архитектуры побудило нас более осмысленно подходить к оценке и к дизайну задач. Аналитики теперь были вынуждены подробнее описывать сценарии работы, а разработчики — планы по работе с задачей. Каждое решение разработчик должен был теперь защитить. А к дизайну задач начали подходить как минимум два разработчика. Это среди прочего позволило увеличить скорость доставки изменений в Dev- и в Master-ветки. Таким образом мы добились еще и уменьшения Time-to-market.
Всё это отлично мэтчится с подходом «Документация как код». Каждый из упомянутых паттернов описан в нашей документации. Более того, часть из них зафиксирована на уровне ADR. Поэтому на ревью команда может ссылаться на договоренности. Правда, сам ADR для этого должен быть принят всей командой.
Но есть и но. Я бы рекомендовал внедрять в проект чистую архитектуру только в том случае, если команда состоит из опытных и одаренных разработчиков. Иначе работать будет сложно. Ну и важно, чтобы использование чистой архитектуры было общим решением. Потому что такой подход означает, что отныне команда разработки старается лучше понять бизнес и хочет говорить на его языке.
Иными словами, придется искоренять саму идею о том, что разработка может существовать отдельно от бизнеса — в том числе и на уровне процессов. Например, прежде чем внедрять чистую архитектуру, мы проводили общекомандные встречи. Решали, за что отвечает каждый человек в команде, какие обязанности у разработчика и как нужно перестроить процессы, чтобы всё работало корректно.
Комментарии и обсуждения статьи на habr.